

Performance
The Fabasoft Integration for OData processes data in of two steps:
- During the first step (“Cube creation”), all objects as defined in the data source are queried and loaded into the OData service. The scope of objects considered is defined by the context of the data source (e.g. Teamroom). If the objects of the query result contain references to instances of classes contained in the data source, these instances are added to the object set. No queries are executed for the object classes “Object”, “User” and “Group”. Instead, the references to these instances are collected in the corresponding tables.
- During the second step (“Table creation”), the values per table are loaded and mapped to the structure as required by the OData query processor. This data is created per table on demand. However, all of the table rows are created independent of the amount of table rows queried.
Keep in mind that any caching within the OData services is performed per user. Thus, if multiple users access an OData service, they all work with their dedicated OData cache.
Performance of the Initial Call to an OData Service
In order to reduce the processing overhead of the initial call to an OData service you can
- reduce the number of entities or tables, and/or
- reduce the number of properties inside entities or tables with high row count.
Try removing unused properties to reduce the overall processing time for each entity. This is most likely the fastest way to resolve such performance issues.
Performance of Subsequent Calls to OData Service
Should the OData service lack performance with regards to subsequent calls, you may increase the value in the Cache Duration field. In this case, the data is stored in the cache for a longer period, hence subsequent calls may reuse the already existing data table.
Performance Optimization “Getting Only X Rows”
In OData request syntax there is a filter targeting the number of rows fetched. It is the “top” command and can be used as followed:
odata/COO.1.506.4.2141/Scrum_Story?$top=500
This top command is also used in some business intelligence tools like Microsoft Power BI when showing a preview of the data.
Because it is commonly used this command has been optimized. That means internally only that amount of entities are fetched and processed. For the user it is transparent – it just does what it should do, just a little faster than other commands.
Precalculation
If reducing the number of attributes as well as splitting up to less entities per OData service does not help to get the result within the given time window (30 minutes), you can use precalculation.
Precalculation is triggered similar like calling an OData service, just with precalc in the URL and a HTTP POST instead of HTTP GET.
The precalculation is performed asynchronously on the server side. That means, when you trigger the precalculation for an OData service, you will quickly get back a 200 OK. In the background it will precalculate the OData service by writing a cache into a Teamroom in the Fabasoft Cloud.
To enable the precalculation, two steps are needed in the OData service:
- Ensure a valid cache duration is entered. 24 hours is our suggestion. That means, you could trigger the precalculation at night and then on the whole day these cached entries are taken to quickly deliver OData results.
- A Teamroom has to be entered below where the cached data is stored. Inside this Teamroom, another Teamroom will be created especially for you.
Please be careful with giving additional permissions on these inner Teamroom to others as it may be that others can see data they normally have no access to.
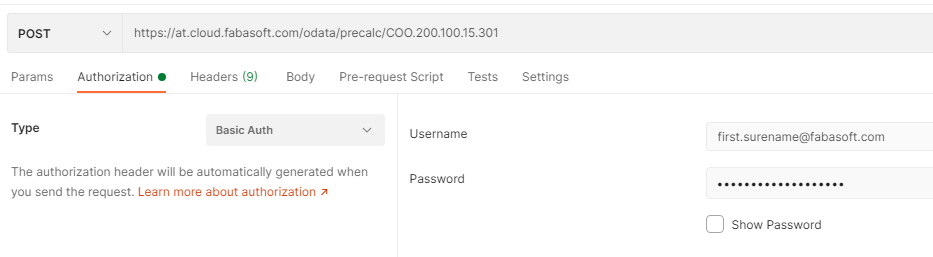
Finally, you have to call the precalculation. If the normal URL for your OData service is
GET https://at.cloud.fabasoft.com/odata/precalc/COO.200.100.15.301
you have to add /precalc after /odata and use the HTTP POST method instead of HTTP GET.
This could be your final URL:
https://at.cloud.fabasoft.com/odata/precalc/COO.200.100.15.301
You can use e.g. curl or Postman to trigger that request. The authentication is the same as on a regular OData request – basic authentication with your username and the OData password from password for applications.
Depending on your OData service and your data, it can take hours to be finished. Triggering it at night time makes sense.
The actual GET OData request should then be way quicker compared to without preloading. Depending on the amount of returned data entries, it can then take seconds to minutes to be finished.